Redis는 많은 서비스에서 사용되고 있다. 주로 조회 API 응답 속도를 빠르게 하기 위해 캐싱에 사용되거나 Lock을 구현하는데 사용됩니다. 이렇게 다양한 곳에 사용되는 Redis는 왜 빠를까요? 크게 3가지 이유를 꼽을 수 있습니다
1. 메모리 기반 데이터 저장소
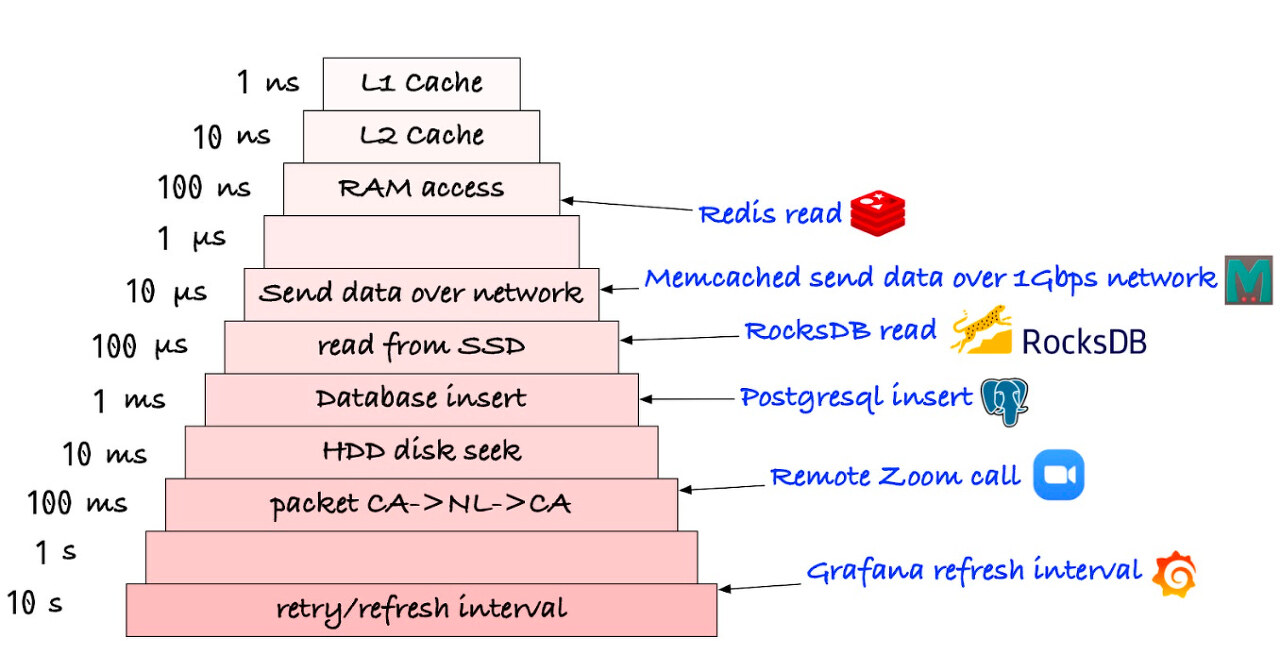
Redis는 디스크 대신 메모리에 데이터를 저장합니다. 메모리에 직접 접근하므로 데이터에 빠르게 접근할 수 있습니다. 메모리는 CPU와 직접적으로 연결되어 있기에 CPU는 빠르게 데이터를 검색할 수 있습니다. 메모리 액세스는 Random Disk I/O보다 빠릅니다. 높은 읽기/쓰기 처리량과 낮은 Latency가 장점인 반면, 메모리의 크기보다 크게 데이터를 저장할 수 없는 단점도 있습니다.
2. I/O 멀티플렉싱과 단일 스레드 모델
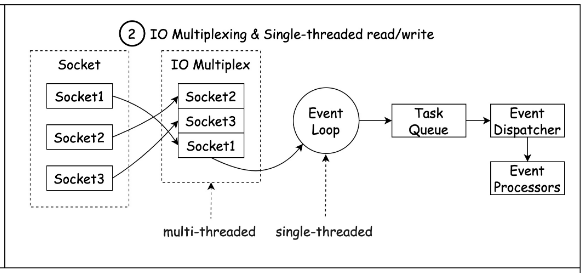
Redis는 비동기 I/O를 사용하여 여러 클라이언트 요청을 동시에 처리할 수 있습니다. 이를 통해 높은 처리량을 유지할 수 있게 됩니다. I/O 모델을 통해 이벤트 루프를 실행하고, 이벤트에 대한 콜백을 실행합니다. 또한 Redis는 단일 스레드 모델을 사용합니다. Redis의 단일 스레드 모델은 다수의 스레드를 사용하는 다른 데이터베이스와 비교하여 많은 장점을 갖고 있습니다. 컨텍스트 전환 비용이 없는 것이 가장 큰 장점 입니다. 다중 스레드를 사용하는 데이터베이스는 스레드 간의 컨텍스트 전환 비용이 발생하거나 락을 사용하고 동기화 하기 위한 메커니즘이 필요하여 처리량이 떨어질 수 있습니다. 하지만 Redis는 단일 스레드로 모든 작업을 처리하므로 이러한 비용이 발생하지 않습니다.
3. 네이티브 데이터 구조
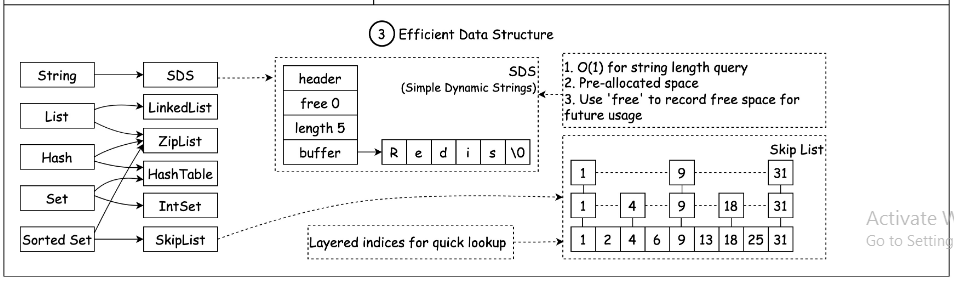
Redis은 단순한 데이터 구조를 사용합니다. 문자열, 리스트, 해시, 집합(Set), 정렬된 집합(Sorted Set) 등 다양한 네이티브 데이터 구조를 지원합니다. 이들 데이터 구조는 가볍고 간단하여 Redis의 메모리 사용량을 최소화하면서 빠른 데이터 처리를 보장합니다. 또한 Redis는 내부적으로 적절히 최적화된 데이터 구조를 사용하기 때문에 매우 빠른 데이터 저장 및 검색을 제공할 수 있습니다.
4. 정리
지금까지 Redis가 빠른 이유에 대해서 정리하면 아래와 같습니다.
- 메모리 기반 데이터베이스다
- Memory Access는 Random Disk I/O보다 속도가 빠르다
- 높은 처리량과 낮은 지연시간(Latency)가 장점이나 메모리 크기보다 넘게 데이터를 저장할 수 없다
- I/O Multiplexing & Single Thread
- 멀티 쓰레드는 Lock과 동기화등이 필요하지만 싱글 쓰레드는 그렇지 않아서 속도에 이점이 있다
- I/O multiplexing을 통해 싱글쓰레드에 시스템 콜을 하며 여러개의 요청을 처리하도록 한다
- 네이티브 데이터 구조
- 효율적인 Low-Level 데이터 구조를 사용한다
- 이는 Disk에 어떻게 효율적으로 데이터를 저장할지 고려하지 않기 때문에 빠른 데이터 저장 및 검색을 제공한다.
댓글